Building a Face Recognition System with the KNN Algorithm
What is Face Recognition?
Face recognition is a computer vision technique that involves identifying and verifying individuals based on their facial features. It has become a popular and widely used technology in various applications.
Applications of Face Recognition
- Security: Access control, surveillance, and law enforcement.
- Payment systems: Biometric authentication for mobile payments.
- Social media: Tagging and recognizing people in photos.
- Entertainment: Facial animation and augmented reality.
- Healthcare: Patient identification and monitoring.
K-Nearest Neighbors (KNN) Algorithm for Face Recognition
The K-Nearest Neighbors (KNN) algorithm is a simple yet effective machine learning algorithm that can be used for face recognition. It works by comparing a new image to the nearest K training images and assigning the most frequent label among those neighbors.
In the context of face recognition, the training data consists of pairs of images and corresponding labels (e.g., names). The KNN algorithm learns the relationship between facial features and identities from this training data. When presented with a new image, it finds the K most similar faces in the training set and predicts the identity based on the majority label among those neighbors.
Data Collection and Preprocessing
Capturing Face Images
To train a face recognition system, you need a dataset of face images. This can be collected in various ways, such as:
- Using a webcam: Capture images of individuals in a controlled environment.
- Using existing datasets: Utilize publicly available datasets like Labeled Faces in the Wild (LFW) or CelebA.
- Creating your own dataset: Collect images from various sources, ensuring diversity in terms of facial expressions, lighting conditions, and angles.
Data Cleaning and Normalization
Once you have collected the data, it's essential to preprocess it for better model performance. This includes:
- Cropping: Remove unnecessary background elements to focus on the facial region.
- Resizing: Ensure all images have a consistent size for input to the KNN algorithm.
- Normalization: Normalize the pixel values to a specific range (e.g., 0-1) for consistent processing.
- Data augmentation: Create variations of the images (e.g., rotations, flips) to improve model robustness.
Preparing Data for Training
- Labeling: Assign labels (e.g., names) to each face image.
- Splitting into training and testing sets: Divide the dataset into training and testing sets to evaluate model performance.
KNN Algorithm Explained
How the KNN Algorithm Works
The K-Nearest Neighbors (KNN) algorithm is a simple yet effective machine learning algorithm for classification and regression tasks. It works by finding the K nearest neighbors to a given data point and assigning the most common label among those neighbors.
In the context of face recognition, the KNN algorithm compares a new face image to the faces in the training dataset. It finds the K closest matches based on a distance metric (e.g., Euclidean distance) and assigns the label (name) that appears most frequently among those neighbors.
Choosing the Right Value for K
The value of K (the number of neighbors to consider) is a hyperparameter that needs to be tuned. A small value of K can make the model more sensitive to noise, while a large value can make it less sensitive to outliers.
The optimal value of K depends on the specific dataset and problem. Experimentation is often necessary to find the best value.
Distance Metrics
The distance metric used to measure the similarity between faces is crucial for the KNN algorithm. Common distance metrics include:
- Euclidean distance: Measures the straight-line distance between two points.
- Manhattan distance: Measures the sum of the absolute differences between corresponding components.
- Minkowski distance: A generalization of Euclidean and Manhattan distances.
- Cosine similarity: Measures the angle between two vectors.
The choice of distance metric depends on the nature of the data and the specific application.
Building the Face Recognition System
Training the KNN Model
Once you have prepared your dataset, you can train the KNN model using the fit() method. This involves learning the relationship between facial features and corresponding labels.
Example:
Making Predictions
To recognize a new face, you can use the trained KNN model to predict its label.
Example:
Evaluating the Model
Evaluate the performance of your face recognition system using appropriate metrics, such as accuracy, precision, recall, and F1-score. You can use the test set to assess the model's ability to generalize to unseen data.
Example:
Code Implementation
File 1 (add-new-face.py):
- Captures face images from the webcam using OpenCV.
- Detects faces in the captured frames using a Haar cascade classifier.
- Resizes the detected faces to a fixed size.
- Stores the captured face images and corresponding labels in pickle files for later use.
File 2 (face_recognition.py):
- Loads the saved face data and labels from pickle files.
- Trains a KNN classifier using the face data and labels.
- Captures frames from the webcam in real time.
- Detects faces in the captured frames.
- Resizes the detected faces and predicts their identities using the trained KNN model.
- Displays the predicted names and bounding boxes on the video frames.
Inputs:
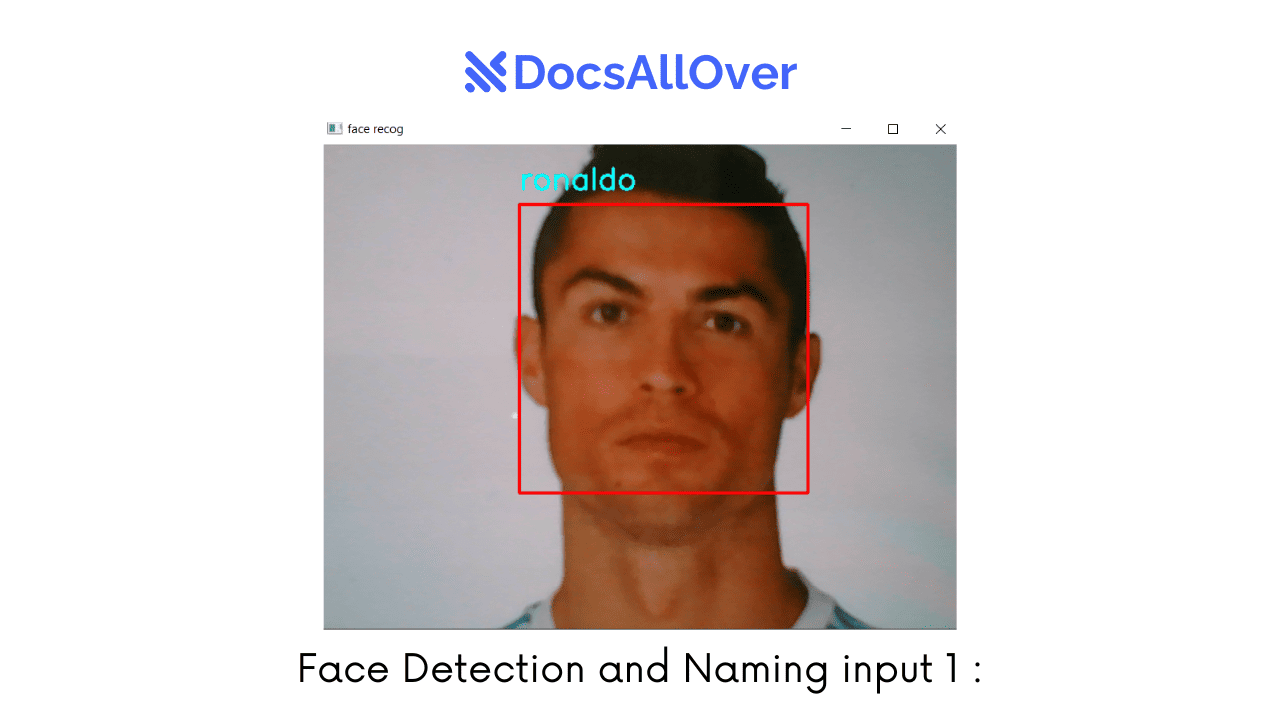

Output:

Challenges and Considerations
Dealing with Occlusions and Variations in Lighting
- Occlusions: Face recognition systems can struggle when faces are partially occluded (e.g., by sunglasses, hair, or objects). To address this, you can use techniques like face alignment, facial landmark detection, or deep learning-based methods.
- Variations in lighting: Changes in lighting conditions can affect the appearance of faces. You can normalize the images to reduce the impact of lighting variations and consider using techniques like histogram equalization or adaptive thresholding.
Improving Accuracy with Larger Datasets
- Data quantity: A larger dataset with diverse faces can improve the accuracy of the face recognition system. Collect data from a variety of individuals under different conditions.
- Data quality: Ensure that the data is high-quality and well-labeled. Remove any images that are unclear or contain errors.
- Data augmentation: Create variations of existing images (e.g., rotations, flips, changes in brightness) to increase the size of the dataset and improve model robustness.
Ethical Implications of Face Recognition
- Privacy: Face recognition systems can raise privacy concerns, as they involve collecting and analyzing personal data. It is important to obtain proper consent from individuals and implement appropriate security measures to protect their privacy.
- Bias: Face recognition systems can be biased if trained on biased data. This can lead to unfair or discriminatory outcomes. It is essential to ensure that the training data is diverse and representative of the population.
- Misuse: Face recognition technology can be misused for surveillance, tracking, or other harmful purposes. It is important to consider the ethical implications and potential consequences of deploying such systems.








