ML Music Recommendation: Hybrid Approach (Content & SVD) with Flask

In today's digital age, we have a universe of music at our fingertips, with countless songs and artists just a click away. While this vast library offers incredible choice, it also presents a challenge: how do we discover new music that resonates with our individual tastes amidst this overwhelming ocean of sound? This is where the magic of music recommendation systems comes into play, acting as our personalized guides to musical discovery.
In this blog post, we'll take you on a journey behind the scenes of building our own AI-powered music recommendation system, designed to suggest tracks you might love based on your listening habits and the characteristics of the music itself. We'll explore the fascinating world of algorithms that learn from data to understand musical preferences and help you find your next favorite song.
Dataset Used: At the heart of our project lies the rich Last.fm dataset, generously made available on Kaggle by Harshal19t (https://www.kaggle.com/datasets/harshal19t/lastfm-dataset). This dataset provides a treasure trove of information about user interactions with music on the Last.fm platform, detailing user listening events, along with metadata about the artists, tracks, and albums involved. It's this wealth of data that fuels our system's ability to understand and predict musical tastes.
Our recommendation system leverages two powerful and complementary techniques:
- Content-Based Filtering: This approach dives into the characteristics of the music you've enjoyed, analyzing elements like the artist, album, and track to find similar sonic landscapes you might appreciate.
- Collaborative Filtering (specifically using Singular Value Decomposition - SVD): This method taps into the collective wisdom of the Last.fm community, identifying users with similar listening patterns to yours and suggesting tracks they've enjoyed, even if those tracks don't share obvious content similarities with your existing favorites.
Diving into the Data: Understanding the Last.fm Dataset
Before we can build a system to recommend music, we first need to understand the fuel that powers it: the data. For our project, we've chosen the Last.fm dataset, a rich collection of user-generated music listening events. Last.fm is a music service that tracks what its users listen to across various platforms and devices, a process known as "scrobbling." This continuous tracking generates a vast amount of data reflecting real-world music consumption patterns.
The dataset we're using, available on Kaggle, provides a snapshot of these interactions. Let's take a closer look at the key columns you'll typically find in such a dataset:
- User ID (or Username): A unique identifier for each user who has listened to music. This allows us to track individual listening histories and preferences.
- Artist: The name of the artist who performed the track.
- Track: The title of the song that was listened to.
- Album: The name of the album the track belongs to (this might be present or have missing values depending on the specific dataset version).
- Timestamp (or Date and Time): A record of when a particular user listened to a specific track. This temporal information can be crucial for understanding trends and user behavior over time.
It's important to note that the Last.fm dataset primarily provides implicit feedback. Unlike explicit feedback, where users actively rate or review items (like movies or products), implicit feedback is derived from user actions. In our case, a listening event implies a positive interaction with a song. This type of data is incredibly valuable for recommendation systems because it reflects natural user behavior at scale, without requiring users to make conscious ratings. However, it also presents challenges, as the absence of a listening event doesn't necessarily mean a user dislikes a song; they might simply not have encountered it yet.
Our initial steps with this dataset involved loading it into a manageable format, typically using libraries like pandas in Python. We then undertook some essential preprocessing to clean the data and prepare it for our recommendation models. This might include:
- Handling missing values: Deciding how to deal with incomplete information, such as missing album names.
- Creating unique identifiers: Generating a unique
item_idfor each song (often by combining artist and track) to easily reference them within our models. - Filtering sparse data: Removing users or songs with very few interactions to focus on more active users and popular items, which can improve the quality and efficiency of our models.
Understanding the nature and structure of the Last.fm dataset is the foundational step in building an effective music recommendation system. With this data in hand, we can now move on to the exciting part: building the algorithms that will help users discover their next favorite tune.
Building the Content-Based Recommendation Engine
Now, let's delve into the first of our recommendation techniques: Content-Based Filtering. At its core, content-based filtering operates on the principle that if you've liked something in the past, you'll likely enjoy similar things in the future. Unlike other methods that consider the behavior of different users, content-based filtering focuses solely on the attributes or features of the items themselves – in our case, the songs.
So, how do we represent a song based on its content? For our music recommendation system, we've leveraged the readily available metadata associated with each track in the Last.fm dataset: artist, album, and track name. We can consider these pieces of information as the defining characteristics or features of a song. For example, a song by "Nirvana" titled "Smells Like Teen Spirit" from the album "Nevermind" has a unique combination of these features.
To understand how similar two songs are based on these textual features, we need a way to quantify this similarity. This is where techniques like TF-IDF (Term Frequency-Inverse Document Frequency) come into play. TF-IDF is a powerful method for converting text data into numerical representations that highlight the importance of different words within a document (in our case, the combined text of artist, album, and track). It works by giving higher weights to words that appear frequently in a specific song's metadata but less frequently across all songs in the dataset. This helps us identify the terms that are most distinctive for each song.
Once we've used TF-IDF to transform the textual metadata into numerical vectors for each song, we need a way to measure how similar these vectors are. A common and effective technique for this is Cosine Similarity. Imagine each song's metadata as a vector in a multi-dimensional space (where each dimension represents a word from our vocabulary). Cosine similarity measures the cosine of the angle between two of these vectors. A cosine value closer to 1 indicates a higher degree of similarity (a smaller angle), meaning the songs are more alike based on their content.
Now, how do we use this to generate recommendations for a user? The process involves the following steps:
- Gather User History: We first look at the songs a particular user has listened to and interacted with positively (based on their listening history in the Last.fm dataset).
- Identify Liked Items: We consider these listened songs as the items the user "likes" or has shown an interest in.
- Find Similar Items: For each of these liked songs, we use our pre-calculated content similarity matrix (based on TF-IDF and cosine similarity) to find other songs in our entire catalog that have high similarity scores.
- Aggregate and Rank: We might aggregate the similarity scores from all the songs the user has liked to get an overall similarity score for other songs.
- Recommend Top N: Finally, we rank all the other songs based on their similarity scores and recommend the top N songs that the user hasn't listened to yet.
The Content-Based Recommendation Engine acts like a knowledgeable music enthusiast who understands the characteristics of different songs and can suggest new tracks that share similar qualities with the music you already enjoy.
Implementing Collaborative Filtering with SVD
Our second powerful recommendation approach is Collaborative Filtering. Unlike content-based methods that look at item features, collaborative filtering operates on the principle that users who have exhibited similar behavior in the past will likely have similar preferences in the future. The core idea is to find patterns in user-item interactions – in our case, who listened to what – and use these patterns to make predictions and recommendations. A common phrase that encapsulates this approach is, "Users who liked this also liked that."
One of the most popular and effective techniques within collaborative filtering is Singular Value Decomposition (SVD). Imagine our user-song interaction data as a large matrix, where each row represents a user, each column represents a song, and the entries indicate whether a user has listened to a particular song (or perhaps the frequency of listens). This matrix is often very sparse, as most users haven't listened to most of the songs in our catalog.
SVD is a matrix factorization technique that aims to decompose this large, sparse matrix into the product of three smaller, denser matrices. These smaller matrices represent lower-dimensional "latent factors" that capture the underlying relationships between users and songs. Think of these latent factors as hidden features or characteristics that influence user preferences and song attributes. For example, a latent factor might represent the "mood" of the music or the "genre affinity" of a user.
Implementing SVD for recommendation systems has become significantly easier thanks to libraries like Surprise in Python. Surprise is a fantastic library specifically designed for building and analyzing recommender systems. It provides implementations of various collaborative filtering algorithms, including SVD, along with tools for data handling and evaluation.
Using Surprise, the process of implementing SVD typically involves these steps:
- Loading Data into Surprise: Surprise has its own data structure for handling recommendation data. We need to format our Last.fm interaction data into this structure, specifying the user, the item (song), and a rating (even if it's implicit, like a binary 1 for a listening event).
- Training the SVD Model: Surprise provides an SVD class that we can initialize with parameters (like the number of latent factors we want to uncover). We then "fit" this model to our training data, allowing the algorithm to learn the underlying patterns and the latent factor representations for users and songs.
So, how does SVD help us uncover these latent factors and predict user preferences? During the training process, SVD tries to find the best lower-dimensional representations for users and songs such that when we multiply the user's latent factor vector with the song's latent factor vector, we get a value that approximates the original interaction (whether the user listened to the song). By learning these latent factors, the model can then predict how a user might interact with a song they haven't encountered before. If the user's latent factors align well with the song's latent factors, the model will predict a high likelihood of interaction, making it a good candidate for recommendation.
SVD in collaborative filtering allows us to move beyond simply recommending what similar users have liked. It helps us discover more nuanced relationships and preferences by uncovering these hidden, underlying factors that connect users and music. This makes it a powerful tool for generating personalized and potentially surprising music recommendations.
From Model to Interface: The Flask Web Application
To make our music recommendation system accessible and user-friendly, we integrated the trained Content-Based and SVD models into a web application built using Flask, a popular and lightweight Python web framework. Flask allows us to create web pages and handle user interactions with relative ease.
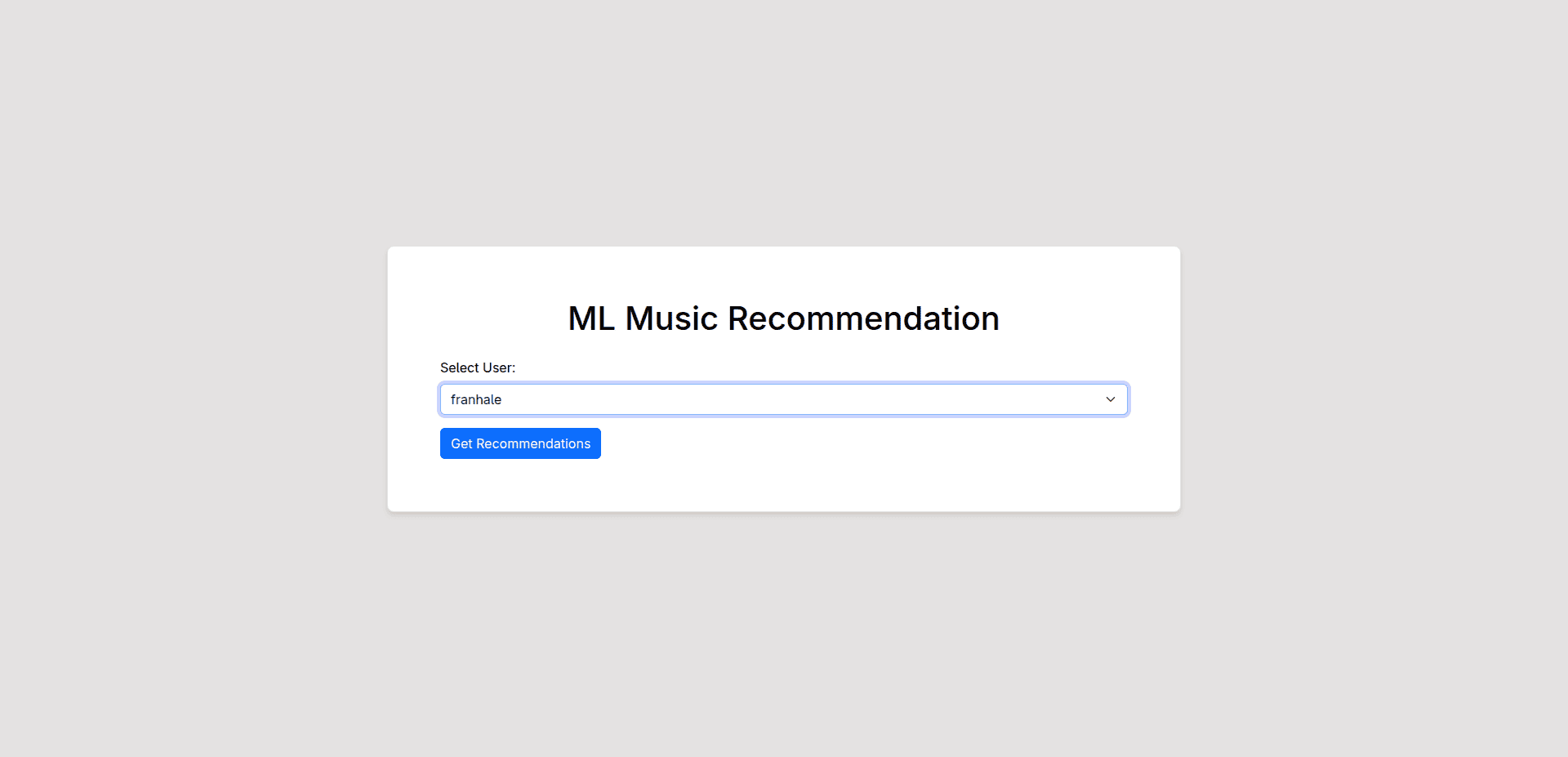
The heart of our user interface is the homepage. Upon visiting the application's URL, users are greeted with a simple yet effective way to get personalized recommendations: a dropdown list containing available usernames from our training dataset. This dropdown is populated with the unique users our models have learned from, allowing anyone to explore potential music suggestions based on the listening patterns within the Last.fm data.
The process of getting recommendations is straightforward. A user simply selects their username (or any username they're curious about) from the dropdown menu. Upon clicking the "Get Recommendations" button, the Flask application springs into action. Here's what happens behind the scenes:
- User Selection: The application receives the selected username from the dropdown.
- Recommendation Generation: The application then utilizes our pre-trained Content-Based and SVD models.
- For the Content-Based model, the application retrieves the listening history of the selected user and finds songs with similar content to those they've enjoyed.
- For the SVD model, the application uses the trained SVD algorithm to predict the songs the selected user is most likely to enjoy based on the latent factors learned from the entire user base.
- Displaying Recommendations: The generated recommendations from both models are then compiled and presented to the user on a dedicated recommendations page (likely using a template like recommendations.html). This page typically displays a list of recommended songs, potentially including information like the artist and track name.
Get Started: Download and Run Locally
Want to try out this music recommendation system on your own machine? Here's a step-by-step guide to get you up and running:
First, you'll need to clone the project repository. Open your terminal or command prompt and navigate to the directory where you want to save the project. Then, use the following command: git clone https://github.com/docsallover/music-recommendation.git
OR Download ZIP: You can download the project zip from github to run on your local machine using the following link.
Download View On GithubThe system has been tested on Python versions up to 3.11. When running it with higher Python versions, you may encounter errors due to compatibility issues with some pip packages.
To use the system, follow these steps:
- Clone the repository (if you haven't already).
- Create a virtual environment (using
venvorvirtualenv) in the project directory. - Activate the virtual environment.
- Install the required dependencies. Run
pip install -r requirements.txt. - (Optional) Train the models using the standalone script. You can run the
main.pyscript to load data, preprocess it, train both recommendation models, evaluate them, and print example recommendations to the console. Runpython main.py. This step is optional as the Flask app also trains the models on startup. - Run the Flask application. Execute the
app.pyfile to start the web interface. Run pythonapp.py. - Open your web browser and navigate to
http://127.0.0.1:5000/(or the address where your Flask app is running). - On the homepage, you will see a dropdown list of available users. Select any username from the list.
- Click the "Get Recommendations" button.
- You will be redirected to the recommendations page, which will display music recommendations generated by both the SVD and Content-Based models for the selected user.
Screenshots
Homepage with User Selection
Recommendations Page