Supervised Learning: A Comprehensive Guide with Examples

Supervised learning is a type of machine learning in which the machine is trained on a set of labeled data. This means that the data includes the desired output for each input. The machine then learns to map inputs to outputs.
Supervised learning is the most common type of machine learning, and it is used in a wide variety of applications, including:
- Image classification: Supervised learning can be used to train machines to classify images, such as distinguishing between cats and dogs.
- Spam filtering: Supervised learning can be used to train machines to filter spam emails.
- Fraud detection: Supervised learning can be used to train machines to detect fraudulent transactions.
- Medical diagnosis: Supervised learning can be used to train machines to diagnose diseases.
- Recommendation systems: Supervised learning can be used to train machines to recommend products or services to users.
How Supervised Learning Works
Supervised learning algorithms typically work in two phases:
- Training phase: The machine is trained on a set of labeled data. This means that the data includes the desired output for each input. The machine learns to map inputs to outputs by finding patterns in the data.
- Prediction phase: Once the machine is trained, it can be used to make predictions on new data. For example, a machine learning algorithm that has been trained to classify images can be used to classify a new image as a cat or a dog.
Types of Supervised Learning Algorithms
There are many different types of supervised learning algorithms, each with its own strengths and weaknesses. Some of the most common types of supervised learning algorithms include:
- Linear regression: Linear regression is a supervised learning algorithm that can be used to predict continuous values, such as the price of a house or the number of customers who will visit a store on a given day.
- Logistic regression: Logistic regression is a supervised learning algorithm that can be used to predict binary values, such as whether or not a customer will click on an advertisement.
- Decision trees: Decision trees are a supervised learning algorithm that can be used to classify data and predict continuous values.
- Support vector machines: Support vector machines are a supervised learning algorithm that can be used to classify data and predict continuous values.
- Random forests: Random forests are a supervised learning algorithm that is an ensemble of decision trees. Random forests are often more accurate than individual decision trees because they reduce overfitting.
Examples of Supervised Learning
Here are some examples of how supervised learning is used in the real world:
- Image classification: Supervised learning is used to train machines to classify images, such as distinguishing between cats and dogs. This technology is used in applications such as self-driving cars and photo sorting apps.
AI photo sorting app designed with GPT-4
byu/visheratin inwebdev - Spam filtering: Supervised learning is used to train machines to filter spam emails. This technology is used by email providers to keep users' inboxes clean.
- Fraud detection: Supervised learning is used to train machines to detect fraudulent transactions. This technology is used by banks and credit card companies to protect customers from fraud.
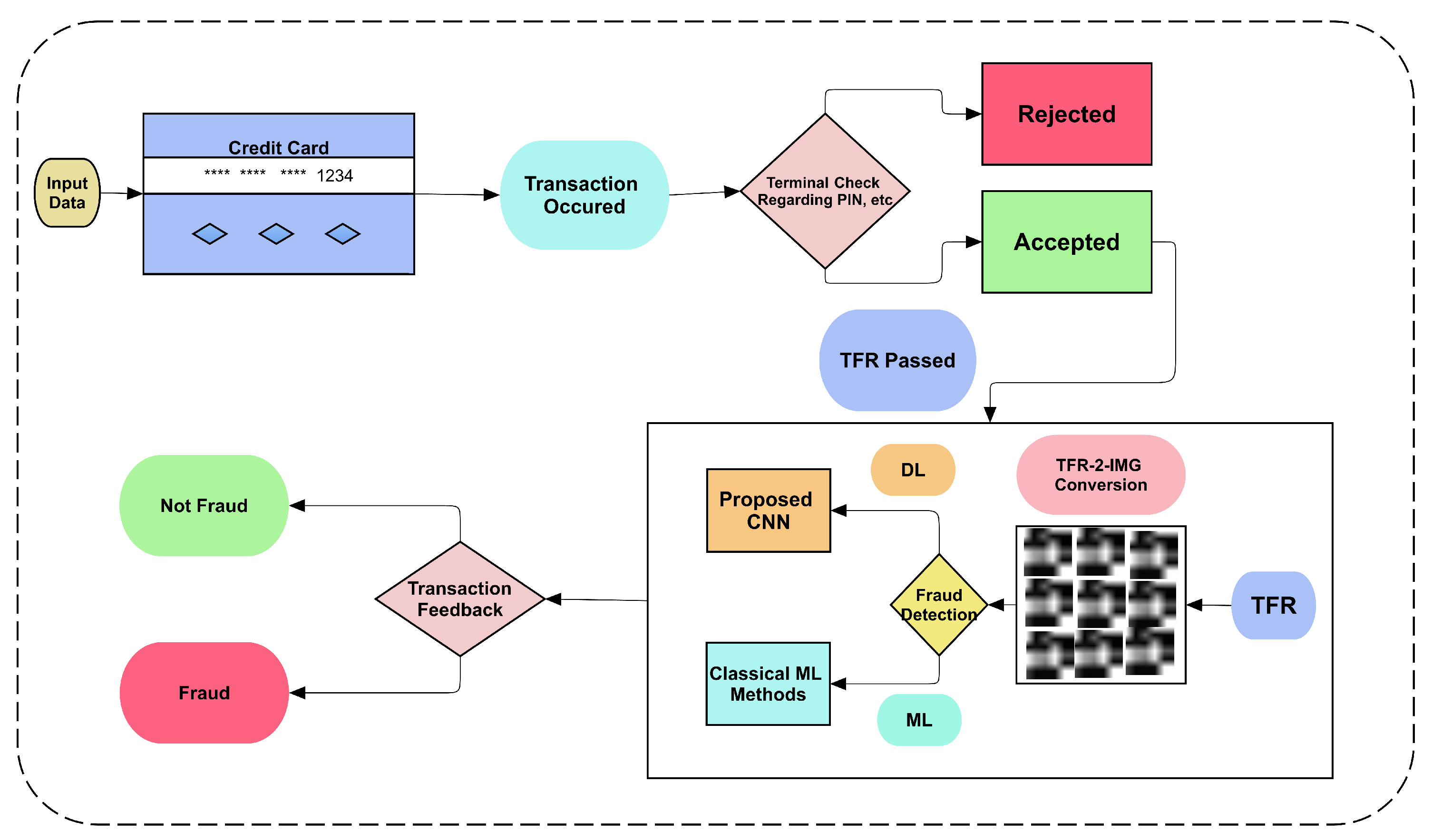
- Medical diagnosis: Supervised learning is used to train machines to diagnose diseases. This technology is used by doctors to help them diagnose diseases more accurately.

- Recommendation systems: Supervised learning is used to train machines to recommend products or services to users. This technology is used by companies such as Amazon and Netflix to recommend products and movies to their users.
Benefits of Supervised Learning
Supervised learning has a number of benefits, including:
- It is relatively easy to understand and implement.
- It can be used to solve a wide variety of problems.
- It can be very accurate, especially when there is a lot of labeled data available.
Drawbacks of Supervised Learning
Supervised learning also has some drawbacks, including:
- It requires a lot of labeled data to train the machine.
- It can be overfit to the training data, meaning that it may not perform well on new data.
- It can be difficult to interpret the results of supervised learning algorithms.